End Times
Google’s DeepMind Machine Generated-Speech Breakthrough Moves Ever Closer To Human Speech
Google’s DeepMind unit, which is working to develop super-intelligent computers, has created a system for machine-generated speech that it says outperforms existing technology by 50 percent.

Google’s DeepMind unit, which is working to develop super-intelligent computers, has created a system for machine-generated speech that it says outperforms existing technology by 50 percent.
“But thou, O Daniel, shut up the words, and seal the book,even to the time of the end: many shall run to and fro, and knowledge shall be increased.” Daniel 12:4 (KJV)
U.K.-based DeepMind, which Google acquired for about 400 million pounds ($533 million) in 2014, developed an artificial intelligence called WaveNet that can mimic human speech by learning how to form the individual sound waves a human voice creates, it said in a blog post Friday. In blind tests for U.S. English and Mandarin Chinese, human listeners found WaveNet-generated speech sounded more natural than that created with any of Google’s existing text-to-speech programs, which are based on different technologies. WaveNet still underperformed recordings of actual human speech.
Many computer-generated speech programs work by using a large data set of short recordings of a single human speaker and then combining these speech fragments to form new words. The result is intelligible and sounds human, if not completely natural. The drawback is that the sound of the voice cannot be easily modified. Other systems form the voice completely electronically, usually based on rules about how the certain letter-combinations are pronounced. These systems allow the sound of the voice to be manipulated easily, but they have tended to sound less natural than computer-generated speech based on recordings of human speakers, DeepMind said.
WaveNet is a type of AI called a neural network that is designed to mimic how parts of the human brain function. Such networks need to be trained with large data sets.
‘Challenging Task’
WaveNet won’t have immediate commercial applications because the system requires too much computational power: it has to sample the audio signal it is being trained on 16,000 times per second or more, DeepMind said. And then for each of those samples it has to form a prediction about what the soundwave should look like based on each of the prior samples. Even the DeepMind researchers acknowledged in their blog post that this “is a clearly challenging task.” source











End Times
In A Humiliating Setback For The Kingdom, Crown Prince Mohammed bin Salman Is Forced To Drastically Scale Back Plans For The Futuristic City Of NEOM

Crown Prince Mohammed bin Salman of Saudi Arabia has been forced to scale back its $1.5 trillion plans for NEOM, a 106-mile linear desert megacity, in a humiliating climb down for the kingdom.
You know, it’s hard to be a dystopian end times dictator bent on world domination these days, just as Crown Prince Mohammed bin Salman over in Saudi Arabia now knows. We told you back in 2022 the plans that the Crown Prince had to build his futuristic city called NEOM. NEOM consists of THE LINE, OXAGON, TOJENA and SINDALAH that would all be the premier representation of the 15-minute city that Klaus Schwab and United Nations want us all to live in. But as Adolf Hitler before him found out, building a kingdom is really hard work, and very, very expensive, even of you’re the Crown Prince of Saudi Arabia.
“For which of you, intending to build a tower, sitteth not down first, and counteth the cost, whether he have sufficient to finish it?” Luke 14:28 (KJB)
But fret not, these cities absolutely are coming, just as everything else we have been threatened with surrounding the United Nations 2030 Agenda is coming. The people who control the technology control the future, and we have already signed on for the technology part. Remember life before the internet? Not so many people do anymore, and besides, as much as we rail against the ‘electronic leash’ of our mobile smart devices, is anyone going to get rid of theirs? No. They are not. We have melded ourselves together with technology, and as we’ve long told you, it’s a 3-step process. First they got us in front of the computer, 1994 – 2007, then they got the computer on us, 2007 – present day, the third and last step according to Revelation 13 will be the computer inside of us. This setback is but a mere ‘blip on the radar’ for Crown Prince Mohammed bin Salman and his city of NOEM, his day is coming soon.
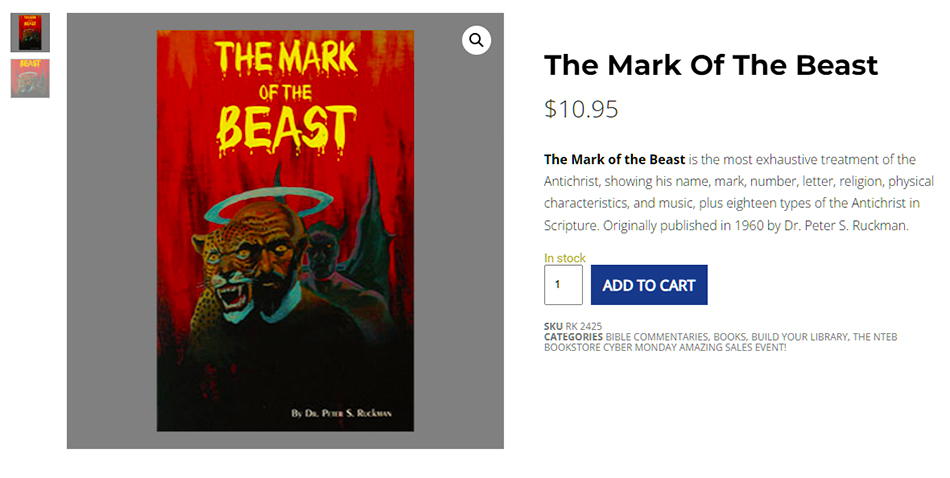
Humiliation for Saudi Arabia as it’s ‘forced to scale back $1.5trillion plans for 106-mile-long city The Line to just 1.5miles with workers already being laid off at desert construction site’
FROM THE DAILY MAIL UK: The Line – part of the country’s audacious and futuristic NEOM project – was meant to be home to around 1.5 million residents by the end of the decade, with plans to ultimately increase its full capacity to nine million people.
Now, according to people familiar with the project, the development will only stretch 1.5 miles and house fewer than 300,000 residents by 2030, according to a new report from Bloomberg citing sources close to the project and documents.
As a result of the reduction to the construction of The Line, at least one contractor has started dismissing workers it employs on the site, the publication has said.
Stunning concept images released by the kingdom in 2022 showed a vast, mirrored structure cutting through the desert near crystal blue ocean waters. It is one of fifteen developments that form the country’s NEOM project – which also includes an industrial city, ports and tourism developments – that have been gradually announced by the kingdom since 2021.
But The Line was the jewel in Crown Prince Mohammed bin Salman’s ‘Vision 2030’ project, which was set in motion to diversify his country’s oil dependent economy, as well as its society and culture, and improve the image it projects on the world stage.
The Kingdom said the project, which is expected to cost $1.5 trillion, would be an ‘unprecedented living experience’ that preserves ‘surrounding nature’. The megacity was to feature two parallel skyscrapers extending across a swathe of desert and mountain terrain, with mirrored facades on the outside.
Saudi officials said it would be built in stages, and would eventually cover a 106-mile stretch of desert along the coast in the western Tabuk province – with its Western tip pointing out over the Red Sea towards Egypt. However, Bloomberg reports that these plans have now been dramatically scaled back – with the 106 mile structure being reduced to just 1.5 miles – a more than 98 percent decrease in size. READ MORE
NEOM and THE LINE in Progress – February 2024
Now The End Begins is your front line defense against the rising tide of darkness in the last Days before the Rapture of the Church
- HOW TO DONATE: Click here to view our WayGiver Funding page
When you contribute to this fundraising effort, you are helping us to do what the Lord called us to do. The money you send in goes primarily to the overall daily operations of this site. When people ask for Bibles, we send them out at no charge. When people write in and say how much they would like gospel tracts but cannot afford them, we send them a box at no cost to them for either the tracts or the shipping, no matter where they are in the world. We have a Gospel Billboard program. We are now broadcasting Bible studies, Podcasts and a Sunday Service 5 times a week, thanks to your generous donations. All this is possible because YOU pray for us, YOU support us, and YOU give so we can continue growing.

But whatever you do, don’t do nothing. Time is short and we need your help right now. The Lord has given us an open door with a tremendous ‘course’ for us to fulfill that will create an excellent experience at the Judgement Seat of Christ. Please pray for our efforts, and if the Lord leads you to donate, be as generous as possible. The war is REAL, the battle HOT and the time is SHORT…TO THE FIGHT!!!
“Looking for that blessed hope, and the glorious appearing of the great God and our Saviour Jesus Christ;” Titus 2:13 (KJB)
“Thank you very much!” – Geoffrey, editor-in-chief, NTEB
End Times
In An Amazing Coincidence, The Pentagon Declassifies And Releases Documents Of A Nuclear Attack Very Much Like The Ending Of New Obama Civil War Movie

The day of nuclear Armageddon: Newly declassified documents reveal in macabre minute-by-minute detail what the end of the world would like, just like in Obama movie ‘Leave The World Behind’
In the closing scene of Barack Obama’s civil war movie ‘Leave The World Behind’, there are two things taking place. The first and main thing is we see 2 of the movie’s characters standing in the woods of Long Island at the water’s edge, watching nuclear bombs exploding over New York City. Bombs launched by the US military on the American people. The second and more arcane thing is we watch a young girl in the safe room of an abandoned mansion watching the last episode of ‘Friends’ on DVD. Took me quite a little while to puzzle that one through, but I think I got it.
“And Jesus said unto him, Friend, wherefore art thou come? Then came they, and laid hands on Jesus, and took him.” Matthew 26:50 (KJB)
In the movie, produced and co-written by former 2-term president of the United States, (and current president from the basement) Barack Hussein Obama, we are watching civil war conducted by the American government against its citizens, you and me. The movie leaves us with the little girl watching the last episode of ‘Friends’ to tell you that the bombs were dropped by our ‘friends’ in the government we elected to keep us safe. Civil War III. This is predictive programming at its razor-sharp best, and yes, the joke is on you. Ba-boom!
Consider this. The first civil war ever fought in America happened in 1776, what we call the Revolutionary War. Yes, Americans fought against the British, but those British were our blood brothers and sisters. It was the Loyalists against the Patriots from the same families who were divided, America was an English colony. Benjamin Franklin worked for the American Patriots, his son William, a Loyalist for the Crown, fought and killed Americans. How crazy is that? America’s second Civil War happened in 1861 between the North and the South. Ever notice how God does things in three’s? I have, and you can bet your bottom dollar the third American Civil War is not only ‘on deck’, but walking to the stage as you read this.
A nuclear strike on the Pentagon is just the beginning of a scenario the finality of which will be the end of civilization as we know it.
FROM THE DAILY MAIL UK: This story, of what the moments after a nuclear missile launch could look like, is based on facts sourced from exclusive interviews with presidential advisers, cabinet members, nuclear weapons engineers, scientists, soldiers, airmen, special operators, Secret Service, emergency management experts, intelligence analysts, civil servants and others who have worked on these macabre scenarios over decades.
As the plans for General Nuclear War are among the most classified secrets held by the US government, the scenario postulated here takes the reader up to the razor’s edge of what can legally be known. Declassified documents, obfuscated for decades, fill in the details with terrifying clarity.

Because the Pentagon is a top target for a strike by America’s nuclear-armed enemies, in the scenario that follows, Washington DC gets hit first with a one megaton thermo-nuclear bomb. ‘A “Bolt out of the Blue” attack against DC is what everyone in DC fears most,’ says Andrew Weber, former assistant secretary of defence for nuclear, chemical and biological defence programmes. ‘Bolt out of the Blue’ is how US Nuclear Command and Control refers to an ‘unwarned large [nuclear] attack’.
This strike on DC initiates the beginning of an Armageddon-like nuclear war that will almost certainly follow. ‘There is no such thing as a small nuclear war,’ is an oft repeated phrase in Washington.
This is the reality of the world in which we live. The nuclear war scenario proposed in this book could happen tomorrow. Or later today. ‘The world could end in the next couple of hours,’ warns General Robert Kehler, the former commander of the United States Strategic Command. A one megaton thermonuclear weapon detonation begins with a flash of light and heat so tremendous it is impossible for the human mind to comprehend.
One hundred and eighty million degrees Fahrenheit is four or five times hotter than the temperature at the centre the Sun.
In the first fraction of a milli-second after the bomb strikes the Pentagon outside Washington DC, there is light. Soft X-ray light with a very short wavelength. The light superheats the surrounding air to millions of degrees, creating a massive fireball that expands at millions of miles per hour.
Within a few seconds the fireball has increased to a diameter of a little more than a mile, its heat so intense that concrete explodes, metal melts or evaporates, stone shatters and people instantaneously convert into combusting carbon. The five-story, five-sided structure of the Pentagon, and everything inside its 6.5 million sq ft of office space, explodes into superheated dust, all the walls shattering with the near-simultaneous arrival of a shockwave. All 27,000 employees perish instantly. Not a single thing in the fireball remains. Nothing. Ground zero is zeroed. READ MORE
Now The End Begins is your front line defense against the rising tide of darkness in the last Days before the Rapture of the Church
- HOW TO DONATE: Click here to view our WayGiver Funding page
When you contribute to this fundraising effort, you are helping us to do what the Lord called us to do. The money you send in goes primarily to the overall daily operations of this site. When people ask for Bibles, we send them out at no charge. When people write in and say how much they would like gospel tracts but cannot afford them, we send them a box at no cost to them for either the tracts or the shipping, no matter where they are in the world. We have a Gospel Billboard program. We are now broadcasting Bible studies, Podcasts and a Sunday Service 5 times a week, thanks to your generous donations. All this is possible because YOU pray for us, YOU support us, and YOU give so we can continue growing.
But whatever you do, don’t do nothing. Time is short and we need your help right now. The Lord has given us an open door with a tremendous ‘course’ for us to fulfill that will create an excellent experience at the Judgement Seat of Christ. Please pray for our efforts, and if the Lord leads you to donate, be as generous as possible. The war is REAL, the battle HOT and the time is SHORT…TO THE FIGHT!!!
“Looking for that blessed hope, and the glorious appearing of the great God and our Saviour Jesus Christ;” Titus 2:13 (KJB)
“Thank you very much!” – Geoffrey, editor-in-chief, NTEB
Earthquakes
A Very Rare Earthquake Rocked New Jersey And The Tri-State Area Right Before We Started Today’s Podcast About The Crazy End Times We Live In
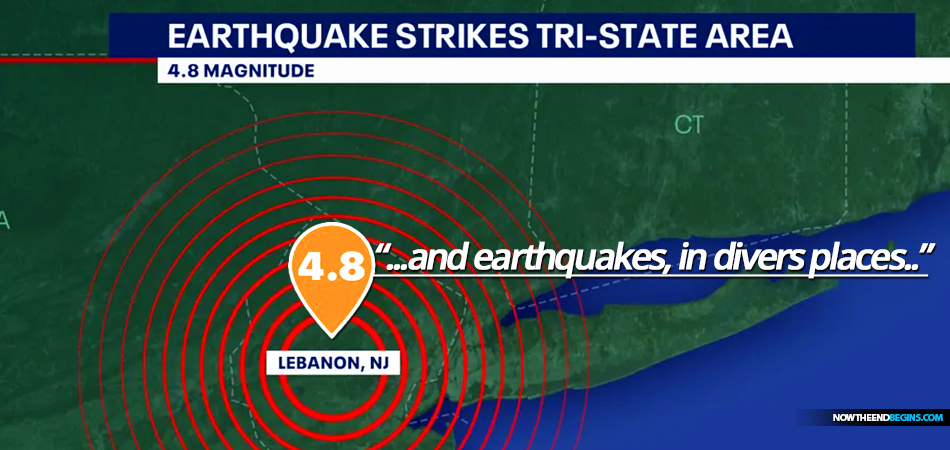
A rare earthquake rocked the New Jersey and New York City area Friday morning, swaying buildings and sending terrified residents into the streets, the strongest temblor to hit the Big Apple in 130 years.
If you are still counting along with us, today is Day 1,481 of 15 Days To Flatten The Curve, and each day brings a new appreciation of the end times we live in. As I was preparing today’s Podcast on the possible coming Bird Flu pandemic, news came of a very rare and powerful earthquake rocked New Jersey, and it was felt in New York City and all the boroughs as well. My good friend and brother in the Lord, Pastor Dave, texted me while we were on-air and said this “I’ve never felt anything like that before went on for a good 20 seconds here at work the whole building shook, sounded like a explosion or freight train coming through. Crazy!” I can’t think of a better way to describe it than that. Crazy.
“This know also, that in the last days perilous times shall come.” 2 Timothy 3:1 (KJB)
Christian, are you still on the sidelines after all this time, what are you waiting for? As the never-ending torrent of bad news continues to assault people’s minds and spirit on a daily basis, we who are saved have been charged with being a witness of the death, burial and resurrection of Jesus Christ. Why don’t you purchase a dozen copies of the excellent witnessing tool “What Must I Do To Be Saved?” by end times author Dr. Bill Grady, and hand them out where you live. You have been called to the fight, so let’s get to it!
Magnitude-4.8 earthquake rocks New Jersey, NYC, tri-state area
FROM THE NY POST: City officials quickly warned people of the danger of potential aftershocks — which already began in the early afternoon in New Jersey, a report said. The preliminary 4.8-magnitude earthquake struck near Lebanon, NJ, around 10:23 a.m., the first time a major tremor hit the area since 2011, according to the US Geological Survey.
“I was doing my morning reporting, and this safe in my office, that’s a ton, starts shaking. The whole room is shaking,” said Monique Horton, who works at the Balmain store on Madison Avenue in Manhattan. “I was just freaked out. Scary, really scary. I’m a New Yorker, my whole life, 36 years, never seen anything like it.”
At the United Nations in Midtown Manhattan, a Security Council address on the Israel-Gaza conflict was interrupted as cameras began shuddering.
The Federal Aviation Administration told airlines to expect flight delays in and out of the Big Apple because of the quake. Some flights bound for New York had already diverted to other airports, according to FlightAware.
US Geological Survey figures indicate the quake might have been felt by a staggering 42 million people.
“This is one of the largest earthquakes on the East Coast in the last century,” Gov. Kathy Hochul said.
The last time an earthquake with a magnitude close to, or above, 5 struck near New York City was back in 1884, the USGS said. That quake appeared to have been centered in Brooklyn. READ MORE
Earthquake rattles New Jersey, New York City and surrounding areas
Now The End Begins is your front line defense against the rising tide of darkness in the last Days before the Rapture of the Church
- HOW TO DONATE: Click here to view our WayGiver Funding page
When you contribute to this fundraising effort, you are helping us to do what the Lord called us to do. The money you send in goes primarily to the overall daily operations of this site. When people ask for Bibles, we send them out at no charge. When people write in and say how much they would like gospel tracts but cannot afford them, we send them a box at no cost to them for either the tracts or the shipping, no matter where they are in the world. We have a Gospel Billboard program. We are now broadcasting Bible studies, Podcasts and a Sunday Service 5 times a week, thanks to your generous donations. All this is possible because YOU pray for us, YOU support us, and YOU give so we can continue growing.
But whatever you do, don’t do nothing. Time is short and we need your help right now. The Lord has given us an open door with a tremendous ‘course’ for us to fulfill that will create an excellent experience at the Judgement Seat of Christ. Please pray for our efforts, and if the Lord leads you to donate, be as generous as possible. The war is REAL, the battle HOT and the time is SHORT…TO THE FIGHT!!!
“Looking for that blessed hope, and the glorious appearing of the great God and our Saviour Jesus Christ;” Titus 2:13 (KJB)
“Thank you very much!” – Geoffrey, editor-in-chief, NTEB





























































-
 George Soros7 years ago
George Soros7 years agoProof Of George Soros Nazi Past Finally Comes To Light With Discovery Of Forgotten Interview
-
 Election 20167 years ago
Election 20167 years agoDEAD POOL DIVA: Huma Abedin Kept Those Hillary Emails That The FBI Found In A Folder Marked ‘Life Insurance’
-
 Election 20167 years ago
Election 20167 years agoCrooked Hillary Campaign Used A Green Screen At Today’s Low Turnout Rally In Coconut Creek FL
-
 George Soros7 years ago
George Soros7 years agoSORE LOSER: George Soros Declares War On America As Violent MoveOn.Org Protests Fill The Streets
-
 Donald Trump7 years ago
Donald Trump7 years agoDonald Trump Will Be 70 Years, 7 Months And 7 Days Old On First Full Day In Office As President
-
 Headline News7 years ago
Headline News7 years agoIf Hillary Is Not Guilty, Then Why Are Her Supporters Asking Obama To Pardon Her? Hmm…
-
 Election 20167 years ago
Election 20167 years agoWikiLeaks Shows George Soros Controlling Vote With 16 States Using SmartMatic Voting Machines
-
 End Times7 years ago
End Times7 years agoFalse Teacher Beth Moore Endorses The Late Term Partial-Birth Abortion Candidate Crooked Hillary